

TL;DR: TF2 Benchmarks don’t have to be hard to write. See example at the bottom and/or tfbm.
“Premature optimization is the root of all evil.” – Donald Knuth
This quote is ubiquitous in software circles, and is arguably even more relevant today than it was back in 1974. However, it is all too often cited when trying to justify lazy coding. Indeed, Knuth goes on to say:
“Yet we should not pass up our opportunities in that critical 3%.”
To be clear, benchmarks aren’t optimizations. Writing benchmarks won’t make your code faster any more than writing tests will fix your bugs. Benchmarks are a critical diagnostic tool for identifying that 3% that should not be ignored and justifying suboptimal performance elsewhere. If you agree with Knuth on the above (and most programmers and software engineers I work with do), then benchmarks should be your friend.
That said, all too often I find myself pouring over repositories with little-to-no benchmarks. In the tensorflow community at least, I put this down to two main reasons:
- outdated tools that require users to work directly with outdated structures like
Graphs andSessions; and - little documentation about how to use them.
This post aims to address both of these, by looking at the tools provided by tensorflow 2 and introducing some higher-level interfaces to streamline micro-benchmark creation and improve reporting.
Motivating Example
Let’s consider one of the most simplest non-trivial operations: transpsoed matrix multiplication, A @ B.T. tf.linagl.matmul probably does a good job with transpose_b=True, but maybe we’re better off with tf.einsum. Maybe a manual transpose would be more performance, or we could somehow achieve better performance by unstacking the rows of B and performing multiple matrix-vector products.
1
2
3
4
5
6
7
8
9
10
11
12
13
import tensorflow as tf
def matmul_transpose(x, y):
return tf.matmul(x, y, transpose_b=True)
def matmul_manual_transpose(x, y):
return tf.matmul(x, tf.transpose(y, (1, 0)))
def matmul_einsum(x, y):
return tf.einsum("ij,kj->ik", x, y)
def matmul_unstack(x, y):
return tf.add_n([tf.linalg.matvec(x, yi) for yi in tf.unstack(y, axis=0)])
How do we compare performance for these different implementations? Micro-benchmarks to the rescue!
Existing Tools
One reason I believe microbenchmarks are so uncommon in the tensorflow research community is a lack of tools for micro-benchmarking, and poor documentation of those that exist. To be clear, there are extensive benchmarks in the tensorflow repository itself - the practice just doesn’t seem to have penetrate the user base at large.
There are two main tools provided by the tensorflow framework for benchmarking code:
- tf.test.Benchmark; and
- tf.profiler (with optional usage via tf.keras.callbacks.TensorBoard).
Without a doubt the recent profiler tool is incredibly helpful for understanding resource utilization and identifying inefficiencies or bottlenecks. There’s an amazing guide here, and I would strongly encourage anyone building and training models to have at least a modest understanding of how to use it. However, in my experience the profiler is best used for understanding entire model performance rather than comparing between different versions of a function or library. For that, Benchmarks really shine. However, based on the documentation it’s not entirely clear how they’re supposed to be used. The following is how I originally wrote benchmarking scripts.
1
2
3
4
5
6
7
8
9
10
11
12
13
def get_args(i=1024, j=1024, k=1024):
return tf.random.normal((i, j)), tf.random.normal((k, j))
def benchmark_matmul_impl(f, **kwargs):
with tf.Graph().as_default() as graph:
x, y = get_args(**kwargs)
output = f(x, y)
with tf.compat.v1.Session(graph=graph) as sess:
bm = tf.test.Benchmark()
bm_result = bm.run_op_benchmark(sess, output)
return bm_result
benchmark_matmul_impl(matmul_transpose)
This gives us some output printed to screen.
entry {
name: "TensorFlowBenchmark.run_op_benchmark"
iters: 10
wall_time: 0.0020650625228881836
extras {
key: "allocator_maximum_num_bytes_GPU_0_bfc"
value {
double_value: 12582912.0
}
}
extras {
key: "allocator_maximum_num_bytes_gpu_host_bfc"
value {
double_value: 8.0
}
}
}
That’s definitely not the most user-friendly reporting, but we’re on the right track. The information is also contained in the value returned from run_op_benchmark, so if we want to compare different implementations we can accumulate results and print the results at the end.
1
2
3
4
5
6
7
8
9
10
11
12
13
impls = (
matmul_transpose, matmul_manual_transpose, matmul_einsum, matmul_unstack
)
names_and_results = [(impl.__name__, benchmark_matmul_impl(impl)) for impl in impls]
for name, result in names_and_results:
print("---")
print(f"name: {name}")
print(f"wall_time: {result['wall_time']}")
extras = result['extras']
for k in sorted(extras):
print(f"{k}: {extras[k]}")
Output:
---
name: matmul_transpose
wall_time: 0.0022330284118652344
allocator_maximum_num_bytes_GPU_0_bfc: 12582912
allocator_maximum_num_bytes_gpu_host_bfc: 8
wall_time_mean: 0.0022828102111816405
wall_time_stdev: 0.000134608013307533
---
name: matmul_manual_transpose
wall_time: 0.0021229982376098633
...
Alright, we seem to be getting somewhere, but there are a few things that need addressing.
Do we really need to still use
Graphs andSessions?
If you’re new to TF, these were key constructs in TF1 and are still operating behind the scenes for much of TF2 functionality, but the tensorflow team is strongly encouraging users to use higher level interfaces like tf.function.
I was somewhat surprised this wasn’t updated with TF2. It turns out I’m not the only one to feel this way, and a bit of digging through the tensorflow source code reveals there’s an implementation in the tensorflow repository that hides the usage of these archaic constructs. Unfortunately it’s not a part of the tensorflow module itself - but that’s nothing a quick copy-paste can’t fix. It also allows you to customize configuration like the device (cpu vs gpu) and whether or not to use JIT compilation.
Can we have a general-purpose interface like pytest for benchmarks?
It turns out this is already supported with the tf.test.Benchmark class and tf.test.main, though it’s entirely undocumented and I’m not sure how it’s supposed to be found. It turns out running a script which calls tf.test.main along with the command line flag --benchmarks=.* (or a more specific filter) with run any methods with names starting with benchmark for tf.test.Benchmark classes defined in any imported modules.
1
2
3
4
5
6
7
8
9
10
11
import tensorflow as tf
class ExampleBenchmark(tf.test.Benchmark):
def benchmark_foo(self):
with tf.Graph().as_default():
out = foo()
with tf.compat.v1.Session() as sess:
self.run_op_benchmark(sess, out)
if __name__ == '__main__':
tf.test.main()
1
python example_benchmark.py --benchmarks=.*
tfbm
Personally, I feel the above leaves a lot to be desired. There’s a lot of boilerplate, I frequently have to consult APIs and accumulating results across different benchmarks and reporting results is a pain. In the past, this has made me less inclined to write benchmarks, and developing new ops that I haven’t benchmarked makes me feel dirty. I decided to bite the bullet and write a module to make things as straight forward as possible. tfbm (tensorflow benchmarks) is the result of that work. In particular, it provides:
- a clean decorator-based API that builds on
tf.test.Benchmark; - a simple CLI for running benchmarks and reporting results (these work with any
tf.test.Benchmark, not just those using thetfbmAPI); and - saving results and comparing saved results (e.g. to compare performance across different versions).
The following example demonstrates usage. See the README.md for more details.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
"""benchmark_matmul.py - benchmarking of different `A @ B.T` implementations."""
import tensorflow as tf
from tfbm import Benchmark, benchmark
def get_factors(i=1024, j=1024, k=1024):
return tf.random.normal((i, j)), tf.random.normal((k, j))
class MatmulBenchmark(Benchmark):
# every benchmark will be repeated for each of these configurations.
BENCHMARK_SPEC = [
benchmark(device="cpu"),
benchmark(device="gpu"),
benchmark(name="XL", args=(4096,) * 3, device="gpu"),
]
# a single @benchmark annotation marks this method to be benchmarked.
@benchmark
def matmul_transpose(self, *args):
return tf.matmul(*get_factors(*sizes), transpose_b=True)
@benchmark
def matmul_manual_transpose(self, *args):
return tf.matmul(*get_factors(*args), transpose_b=True)
@benchmark
def matmul_einsum(self, *args):
return tf.einsum("ij,kj->ik", *get_factors(*sizes))
# benchmark annotations can also be used to specify additional configuration
# multiple annotations can be used, in which case multiple benchmarks will be run.
# `matmul_unstack` will be benchmarked 6 times - one for each
# (`BENCHMARK_SPEC`, @benchmark) combination. In the event of conflict,
# configurations specified in method decorators will override those from
# `BENCHMARK_SPEC`
@benchmark(xla_jit=True)
@benchmark(xla_jit=False)
def matmul_unstack(self, *args):
x, y = get_factors(*args)
return tf.add_n([tf.linalg.matvec(x, yi) for yi in tf.unstack(y, axis=0)])
1
python -m tfbm benchmark_matmul.py --group_by=device,spec --style=markdown
Sample output:
Results for device=gpu,spec=None Uniform results:
| run_id | cls | device | iters |
|---|---|---|---|
| NOW | Matmul | gpu | 10 |
Varied results:
| test | wall_time (us) | max_mem_GPU_0_bfc (Mb) | max_mem_gpu_host_bfc (b) | xla_jit |
|---|---|---|---|---|
| matmul_unstack_xla_gpu | 296.474 | 8.000 | 49.000 | True |
| matmul_transpose_gpu | 1385.57 | 12.0 | 8.000 | False |
| matmul_manual_transpose_gpu | 1471.639 | 12.0 | 8.000 | False |
| matmul_einsum_gpu | 1499.891 | 12.0 | 8.000 | False |
| matmul_unstack_gpu | 51507.950 | 4104.000 | 12.0 | False |
The command line even has colors!
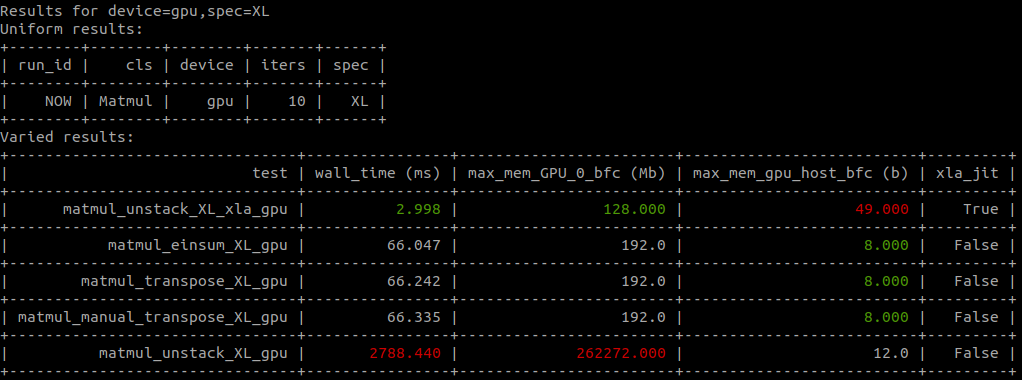
As a side note, I’m not entirely sure I trust the numbers for xla_jit runs. The code that actually does the benchmarks is almost identical to that in the main tensorflow repository though - i.e. I doubt it’s down to something introduced by tfbm.
Conclusion
Micro-benchmarks are important for delivering performant code. The existing tf.test.Benchmark infrastructure provides us with the raw tools to get the job done, and with a little work you can be confident you’re getting the best from your code, and monitor for unintended degredations from code changes. tfbm provides a high level interface and convenient CLI for comparing implementations and saving runs for comparison across software versions.
Feel free to post any questions below. Bug reports, feature requests or general feedback also welcome on the tfbm repository - I’d love to know what you think.